logdistributor
Improvements and Future Work
This document outlines potential improvements and future work for the log distributor project:
Improvements
Given more time, the following improvements could be made to address the identified issues and enhance the overall system:
- Use gRPC (Protobufs) instead of HTTP
- Use clustered setup for the distributor
- Better management of shared state
- FastAPI with multiple workers
- Comprehensive testing suite
- Unit tests for individual components
- Integration tests for end-to-end scenarios
- Migrate to Apache Pekko
gRPC (Protobufs) Instead of HTTP (Increases performance and throughput)
Special consideration was given to using gRPC instead of HTTP for the communication between the log emitter, distributor and analysers but due to added complexity in the implementation with respect to Akka gRPC I chose to stick with HTTP Rest for now. gRPC provides better performance and type safety compared to HTTP, especially for high-throughput applications. The log packets could be defined using Protocol Buffers, which would allow for more efficient serialization and deserialization. This would also enable better integration with other systems that use gRPC, such as microservices architectures. All three services (distributor, analysers, and frontend) could benefit from using the autogenerated grpc stubs for communication, reducing the amount of boilerplate code needed for HTTP handling.
Using clustered setup for the distributor
The current implementation of the distributor service is a single instance. For better scalability and fault tolerance, it would be beneficial to implement a clustered setup using Akka Cluster or Apache Pekko Cluster. This would allow multiple instances of the distributor to run in parallel, distributing the load and providing redundancy in case of failures.
Dynamic Scaling of Worker Actors
Dynamic scaling of worker actors is a potential improvement for the log distributor system. The idea is to dynamically adjust the number of worker actors based on the load and concurrent users. This would involve first studying how load affects the performance of the system and what effects the worker size has on performance. Once this understanding is established, a mechanism could be implemented to dynamically scale the number of worker actors based on current load and user count. This could involve monitoring system performance metrics such as CPU usage, memory usage, and response times, and adjusting the number of workers accordingly. This would help ensure that the system can handle varying loads efficiently without overloading any single worker actor.
Better Management of Shared State
Approach 1
Using CRDT for the distributor instead of Singleton Shared State
The current implementation of the distributor uses a singleton shared state to manage the registered analysers and their health status. This approach can lead to bottlenecks and single points of failure. Instead, using Conflict-free Replicated Data Types (CRDTs) would allow for a more distributed and resilient state management system. CRDTs enable multiple nodes to update the state independently while ensuring eventual consistency, which is ideal for a distributed system like the log distributor. CRDT would be a very good fit to maintain information about the traffic routing.
Using independent failure and recovery detector per worker
CRDT would not be a good choice for the failure and recovery detection of analysers. Instead, each worker actor should have its own failure and recovery detector thread. This would allow for more granular control over the health monitoring of analysers and reduce the risk of false positives or negatives in health checks. Each worker could independently determine the health status of its assigned analyser, improving overall system reliability.
Approach 2
Not using any shared state at all
An alternative approach to managing the state of the distributor is to avoid using any shared state altogether. Instead, each worker actor could maintain its own local state regarding the analysers it interacts with. This would eliminate the need for a centralised singleton state and reduce contention between actors. Each worker would be responsible for its own health checks and routing decisions, allowing for greater flexibility and scalability. The ratio, if maintained properly, would ensure that the distribution of packets is still balanced across the analysers.
This approach needs independent failure and recovery detection per worker as well, similar to the CRDT approach. Each worker would need to implement its own logic for detecting analyser failures and recovering from them, ensuring that the system remains responsive and resilient.
FastAPI with Multiple Workers
The FastAPI analysers are currently run with a single worker. This is because they maintain state of the packets they have processed and the health of the analysers. However, this can lead to performance bottlenecks under high load, as all requests are handled by a single worker. Running multiple workers would allow for better parallelism and improved throughput. Multiple workers can maintain state in shared storage (e.g., Redis, database) or use a distributed cache to share the state across workers. This would allow the FastAPI service to handle more requests concurrently while still maintaining the necessary state information.
Comprehensive Testing Suite
To ensure the robustness of the system, a more comprehensive testing suite is needed. This should include:
- Network Partitioning Tests: Simulate network failures and partitions to ensure the system can handle such scenarios gracefully.
- Slow API Response Tests: Test how the system behaves when analysers respond slowly or are overloaded.
- Long-Term Stability Tests: Run the system under sustained load for extended periods to identify any performance degradation.
Unit Tests for individual Components
Unit tests should be implemented for individual components of the system, including:
- Routing Algorithm: Write Unit Test for the correctness of the routing algorithm under various scenarios, including different analyser weights and health statuses.
- Distributor Actor: Write Unit Test for the behaviour of the distributor actor, including how it handles incoming packets and interacts with worker actors.
- Worker Actors: Write Unit Test for the logic of worker actors, including how they manage their local state and interact with analysers.
- FastAPI Endpoints: Write Unit Test for the FastAPI endpoints to ensure they handle requests correctly and maintain the necessary state.
Integration Tests for End-to-End Scenarios
Integration test using run scripts for the simulation, a log collection system from all the services and then testing the logs for correctness. An example fo this testing strategy is used in my previous project at Distributed Algorithms
Possible Implementation Architecture:
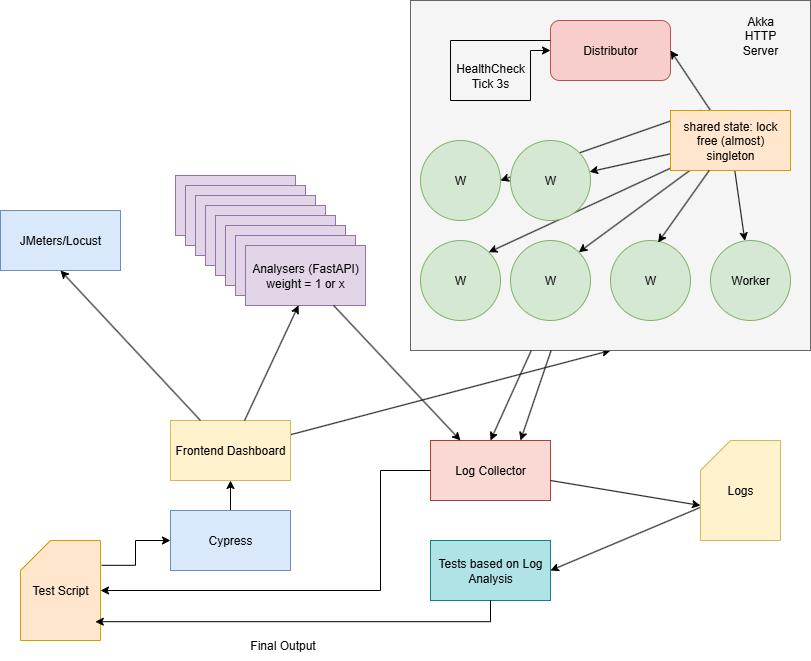
Might be too complicated but:
- Cypress or Playwright for end-to-end testing of the system using the frontend that’s already built.
- Different scenarios can be tested by using different configurations of the system, such as different numbers of analysers, different weights, and different health statuses.
- Log collection system to collect logs from all services and then test the logs for correctness.
What does testing for log correctness mean?
- Checking if the total number of packets received logged by the analysers matches the total number of packets sent by the distributor (No packets are lost).
- Collecting final log from the analysers and checking if the distribution is followed.
- Checking if no packets were routed to an analyser after it was marked as down (ensures that there is no delay in the failure detection and recovery process), this will also ensure that the packets are not lost.
Apache Pekko Instead of Akka (Solves 1st issue)
The project currently uses Akka HTTP for the distributor service. However, Akka has changed its licensing model from open source to a commercial license, which may not be suitable for all users. Apache Pekko is a fork of Akka that retains the original open source license, making it a more suitable choice for future development. Migrating to Pekko would ensure continued compatibility with open source principles.